Retrieval-Augmented Generation (RAG): A Practical Guide with Hands-on Tutorial
Learn how to build a Retrieval-Augmented Generation (RAG) system from scratch with a practical Python tutorial. Understand the mechanics and benefits of RAG in NLP.
Retrieval-Augmented Generation (RAG): A Practical Guide with Hands-on Tutorial
Introduction:
In the rapidly evolving world of Natural Language Processing (NLP), Retrieval-Augmented Generation (RAG) has emerged as a game-changer. It bridges the gap between static language models and the dynamic nature of real-world information, offering a powerful approach to generate more accurate, relevant, and context-aware responses. In this blog post, we will not only delve into the theoretical underpinnings of RAG but also provide a practical, hands-on tutorial so that you can get your hands dirty and implement it yourself.
Understanding Retrieval-Augmented Generation (RAG)
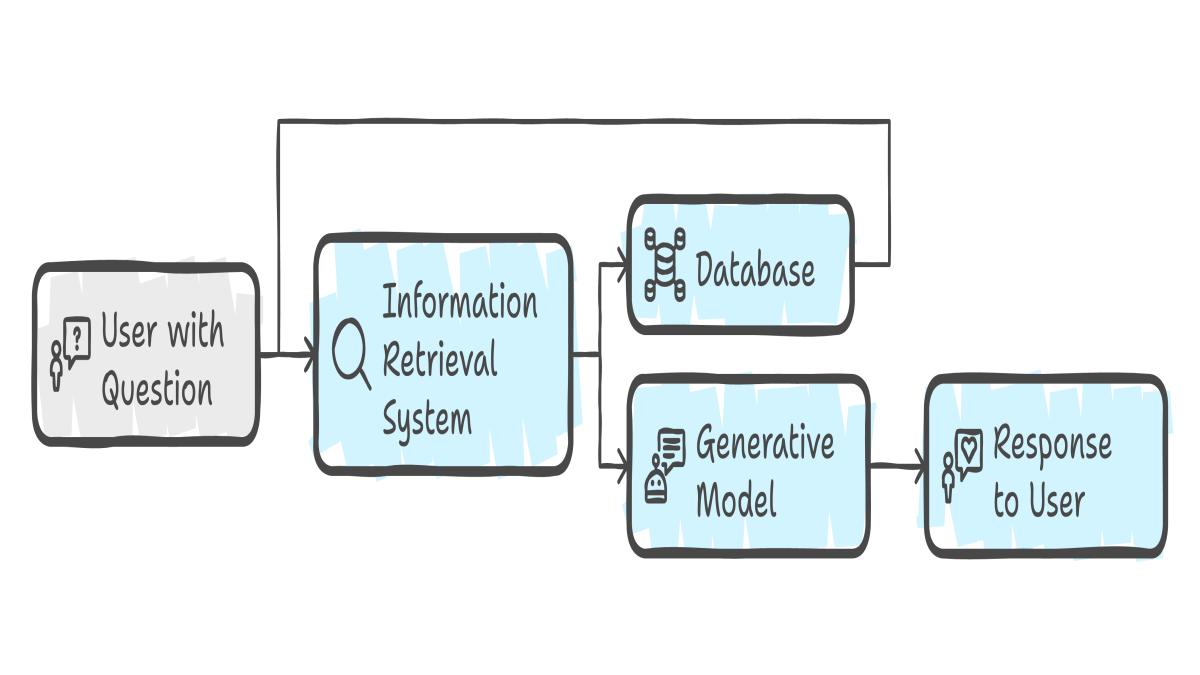
As discussed in detail in the previous post, RAG combines the strengths of two key components:
- Retrieval: Accessing and fetching relevant information from an external knowledge source based on the user’s query.
- Generation: Using a generative language model to produce a response by incorporating the retrieved information.
The process unfolds like this:
- User Query: The user asks a question or provides a prompt.
- Retrieval: The system uses a retrieval engine to find relevant documents or snippets from the knowledge source.
- Augmentation: The retrieved information is added to the original query, creating an enriched context for the language model.
- Generation: The language model generates a response based on this augmented prompt.
Why RAG Matters
- Improved Accuracy: RAG reduces hallucinations by grounding the generative process in factual information.
- Up-to-Date Information: It allows access to real-time knowledge from external sources.
- Enhanced Context: The model can generate responses considering a wider context, thanks to the retrieved information.
- Increased Transparency: You can trace back the sources of information, making the process more explainable.
Hands-on Tutorial: Building a Simple RAG System
In this tutorial, we’ll build a basic RAG system using Python and popular NLP libraries. We will use a very simple “knowledge base” to keep the tutorial easy to follow.
Prerequisites:
- Python 3.7+
- Basic understanding of Python
- Libraries:
transformers,sentence-transformers,faiss-cpu
You can install them with pip:
1
pip install transformers sentence-transformers faiss-cpu
Step 1: Creating a Simple Knowledge Base
For simplicity, we’ll define a list of strings as our knowledge base. In a real-world scenario, this would be a database or set of documents.
1
2
3
4
5
6
7
8
9
10
11
knowledge_base = [
"The capital of France is Paris.",
"The Eiffel Tower is located in Paris.",
"Paris is known for its beautiful architecture and museums.",
"The Mona Lisa is in the Louvre Museum in Paris.",
"The Louvre Museum is one of the most famous museums in the world.",
"Machine learning is a subfield of artificial intelligence.",
"Deep learning is a type of machine learning.",
"Natural Language Processing is used for text analysis.",
"Transformers are a powerful architecture in NLP."
]
Step 2: Indexing the Knowledge Base
To enable efficient retrieval, we’ll use sentence embeddings and the FAISS library to create an index.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
# Load a sentence embedding model
model = SentenceTransformer('all-mpnet-base-v2')
# Generate embeddings for our knowledge base
embeddings = model.encode(knowledge_base)
embeddings = np.array(embeddings).astype("float32")
# Create an index
dimension = embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(embeddings)
Step 3: Retrieval Function
Let’s create a function that, given a user query, will retrieve the most relevant information from our knowledge base.
1
2
3
4
5
def retrieve_information(query, top_k=2):
query_embedding = model.encode(query).reshape(1, -1).astype("float32")
D, I = index.search(query_embedding, top_k)
return [knowledge_base[i] for i in I[0]]
Step 4: Generation Function
We’ll use a pre-trained transformer model to generate a response by leveraging the retrieved information.
1
2
3
4
5
6
7
8
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
def generate_response(query, retrieved_info):
augmented_prompt = f"Given the following context: {retrieved_info}. Answer the question: {query}"
response = generator(augmented_prompt, max_length=100, num_return_sequences=1)[0]['generated_text']
return response
Step 5: Putting it All Together
Now let’s create the main function which uses all the previously defined functions to run RAG.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def rag_system(query):
retrieved_info = retrieve_information(query)
response = generate_response(query, retrieved_info)
return response
# Example usage
query = "Where is the Mona Lisa located?"
response = rag_system(query)
print(f"Query: {query}")
print(f"Response: {response}")
query = "What are some use cases of NLP?"
response = rag_system(query)
print(f"Query: {query}")
print(f"Response: {response}")
query = "What is the capital of France?"
response = rag_system(query)
print(f"Query: {query}")
print(f"Response: {response}")
Complete Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
from transformers import pipeline
# Step 1: Creating a simple knowledge base
knowledge_base = [
"The capital of France is Paris.",
"The Eiffel Tower is located in Paris.",
"Paris is known for its beautiful architecture and museums.",
"The Mona Lisa is in the Louvre Museum in Paris.",
"The Louvre Museum is one of the most famous museums in the world.",
"Machine learning is a subfield of artificial intelligence.",
"Deep learning is a type of machine learning.",
"Natural Language Processing is used for text analysis.",
"Transformers are a powerful architecture in NLP."
]
# Step 2: Indexing the knowledge base
model = SentenceTransformer('all-mpnet-base-v2')
embeddings = model.encode(knowledge_base)
embeddings = np.array(embeddings).astype("float32")
dimension = embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(embeddings)
# Step 3: Retrieval Function
def retrieve_information(query, top_k=2):
query_embedding = model.encode(query).reshape(1, -1).astype("float32")
D, I = index.search(query_embedding, top_k)
return [knowledge_base[i] for i in I[0]]
# Step 4: Generation function
generator = pipeline('text-generation', model='gpt2')
def generate_response(query, retrieved_info):
augmented_prompt = f"Given the following context: {retrieved_info}. Answer the question: {query}"
response = generator(augmented_prompt, max_length=100, num_return_sequences=1)[0]['generated_text']
return response
# Step 5: Putting it all together
def rag_system(query):
retrieved_info = retrieve_information(query)
response = generate_response(query, retrieved_info)
return response
# Example usage
query = "Where is the Mona Lisa located?"
response = rag_system(query)
print(f"Query: {query}")
print(f"Response: {response}")
query = "What are some use cases of NLP?"
response = rag_system(query)
print(f"Query: {query}")
print(f"Response: {response}")
query = "What is the capital of France?"
response = rag_system(query)
print(f"Query: {query}")
print(f"Response: {response}")
Running the Code:
Save the code in a file named rag_tutorial.py and execute it using python rag_tutorial.py.
Output
You’ll notice that the model outputs something that is relevant, but as the knowledge base and prompt are simple, the answer might not be perfect.
Further Improvements:
- Use a larger knowledge base: Replace the list of strings with actual documents loaded from a file or database.
- Fine-tune embeddings: Use a more sophisticated embedding model tuned for your specific domain.
- Explore other language models: Experiment with different text generation models.
- Fine-tune the generator model: The gpt2 is a baseline model, fine-tuning it on specific tasks and data can significantly boost accuracy.
- Add more sophisticated retrieval methods: Techniques such as dense retrieval or keyword-based search in conjunction with embeddings.
- Iterative retrieval and refinement: Implement an iterative process to allow the system to retrieve more information if the first round was insufficient.
Conclusion:
Retrieval-Augmented Generation is a promising approach for building more accurate and reliable NLP applications. By combining the capabilities of retrieval and generative models, you can create systems that can access real-time knowledge and generate contextually relevant responses. This tutorial provided a basic introduction to implementing RAG. Explore further improvements to develop a more robust RAG system for your specific use cases. Happy coding!